AudioComposer
AudioComposer: Towards Fine-grained Audio Generation with Natural Language Descriptions
Abstract
Current Text-to-audio (TTA) models mainly use coarse text descriptions as inputs to generate audio, which hinders models from generating audio with fine-grained control of content and style. Some studies try to improve the granularity by incorporating additional frame-level conditions or control networks. However, this usually leads to complex system design and difficulties due to the requirement for reference frame-level conditions. To address these challenges, we propose AudioComposer, a novel TTA generation framework that relies solely on natural language descriptions (NLDs) to provide both content specification and style control information. To further enhance audio generative modeling, we employ flow-based diffusion transformers with the cross-attention mechanism to incorporate text descriptions effectively into audio generation processes, which can not only simultaneously consider the content and style information in the text inputs, but also accelerate generation compared to other architectures. Furthermore, we propose a novel and comprehensive automatic data simulation pipeline to construct data with fine-grained text descriptions, which significantly alleviates the problem of data scarcity in the area. Experiments demonstrate the effectiveness of our framework using solely NLDs as inputs for content specification and style control. The generation quality and controllability surpass stateof-the-art TTA models, even with a smaller model size. The code is available in AudioComposer.
Method
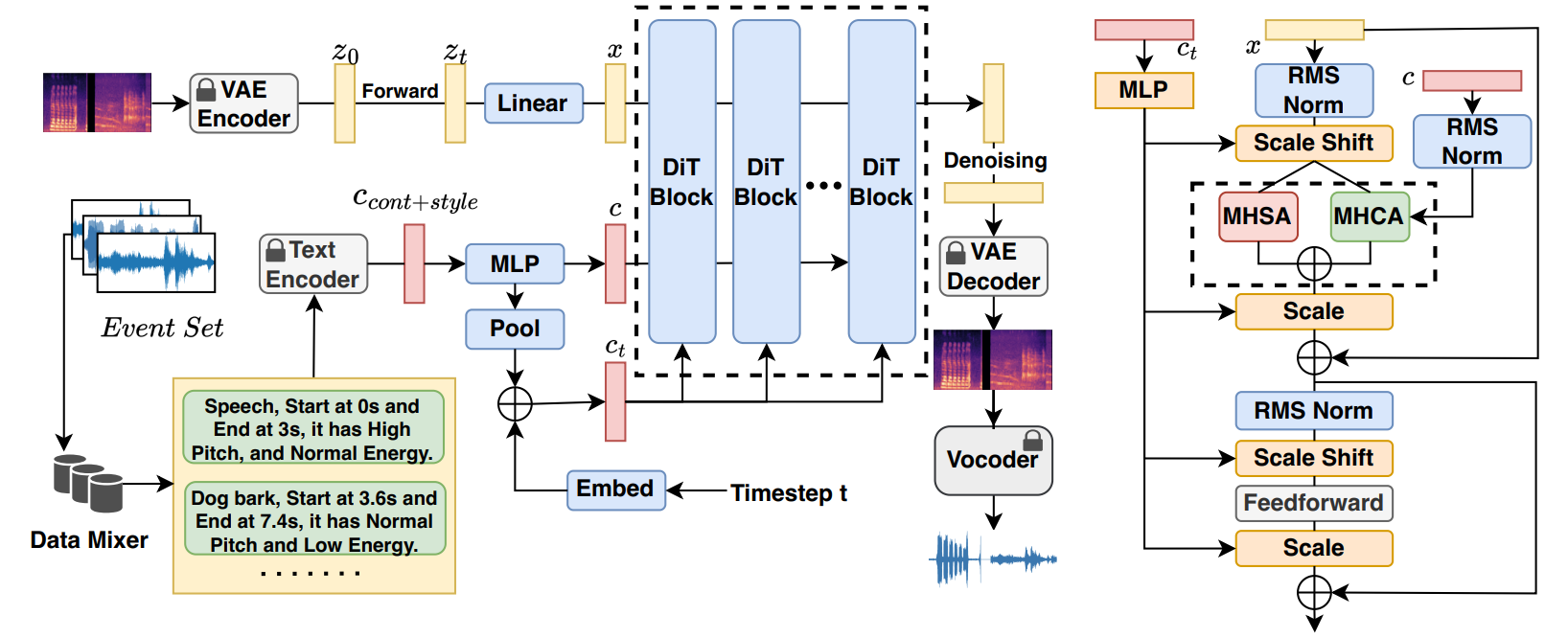 In the following, we will present some samples generated using our AudioComposer.
In the following, we will present some samples generated using our AudioComposer.
AudioCondition test set
| “Water tap, faucet”, Start at 5.02s, End at 7.32s. “Female speech, woman speaking”, Start at 7.4s, End at 10s. |  |
 |
 |
 |
 |
| “Alarm”, Start at 0.14s, End at 2.54s. “Alarm”, Start at 3.4s, End at 10s. “Male speech, man speaking”, Start at 5.24s, End at 10s. |  |
 |
 |
 |
 |
| “Dishes, pots, and pans”, Start at 0.01s, End at 1.14s. “Dishes, pots, and pans”, Start at 8.59s, End at 9.27s. |  |
 |
 |
 |
 |
| “Female speech, woman speaking”, Start at 0s, End at 0.63s. |  |
 |
 |
 |
 |
| “Cutlery, silverware”, Start at 3.91s, End at 5.2s. |  |
 |
 |
 |
 |
| “Female speech, woman speaking”, Start at 0s, End at 2.68s. “Blender”, Start at 4.24s, End at 10s. |  |
 |
 |
 |
 |
AudioTPE test set
Pitch and energy are divided into three levels: low / normal / high. You can distinguish the category according to the normal pitch and normal energy of the reference pitch & energy
| “dog bark”, Start at 0s, End at 3.43s, it has Low Pitch and High Energy. “Yell, human shout”, Start at 3.43s, End at 10s, it has High Pitch and Normal Energy”. |  |
 |
 |
 |
 |
dog bark: Yell: |
| “Cheering, shout”, human group”, Start at 0s, End at 8.43s, it has Normal Pitch and Normal Energy. “Explosion”, Start at 8.43s, End at 10s, it has Normal Pitch and Normal Energy. |  |
 |
 |
 |
 |
Cheering: Explosion: |
| “Drill, power tool”, Start at 0s, End at 3.7s, it has Normal Pitch and Normal Energy. “keyboard typing”, Start at 3.7s, End at 8.09s, it has High Pitch and Normal Energy. “Dog”, Start at 8.09s, end at 10s, it has Low Pitch and Low Energy. |  |
 |
 |
 |
 |
Drill: keyboard: Dog: |
| “Laughter”, Start at 0s, End at 6.88s, it has Low Pitch and Low Energy. “Piano, keyboard_(musical)”, Start at 6.88s, End at 10s, it has Low Pitch and Normal Energy. |  |
 |
 |
 |
 |
Laughter: Piano: |
AudioCaps test set
The FAD is slightly worse because we did not use the relative pressure-based data augmentation strategies proposed in Tango.
| Model | #Params | Objective Metrics | ||
|---|---|---|---|---|
| FD↓ | KL↓ | FAD↓ | ||
AudioCaps Demo
| An emergency siren wailing followed by a large truck engine running idle | ||||
| A man speaks as food sizzles followed by some cracks | ||||
| A train sounds horn while the engine taps | ||||
| A man speaks with others speaking in the distance and traffic passing with a few horns honking |